The growing threat to privacy from big data forensics and false positives
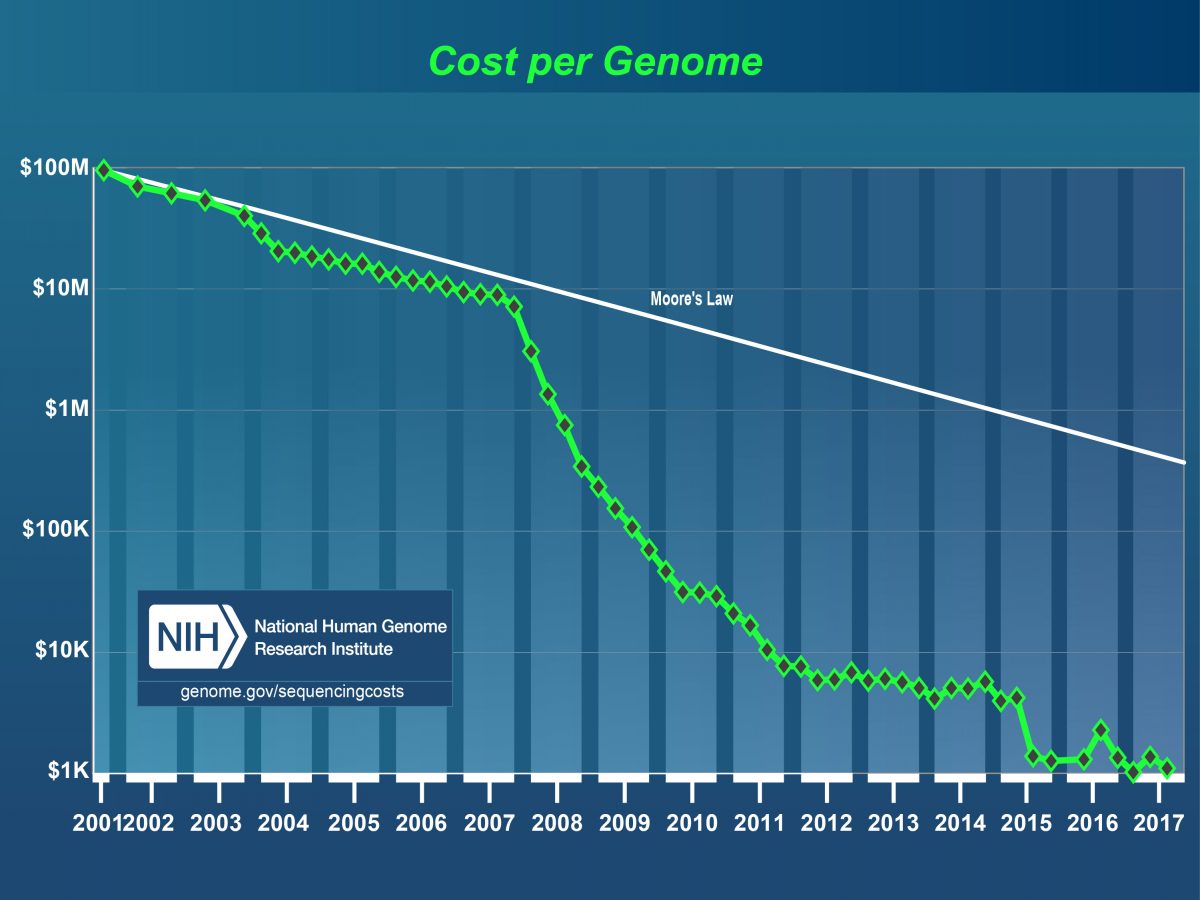
The cost of sequencing the DNA found in genomes has been decreasingly rapidly in recent years. Since 2008, it has been falling even faster than the well-known Moore’s Law for semiconductor prices, and today a human genome can be sequenced in its near-entirety for $1000 or less. Similarly, partial sequencing costs have dropped dramatically, allowing criminal investigations to analyze multiple DNA specimens found at a crime scene as a matter of course. DNA forensics have become a crucial tool because of their specificity. Since our DNA is essentially unique, it can act as the perfect identification system – one that exists naturally, and does not need to be set up or imposed on people by law. However, as DNA is used more widely to aid crime investigations, so some of its limitations have begun to emerge, with important implications for privacy.
For example, just because there is a perfect match of DNA found on a crime victim with that of someone with a criminal record whose details are held on a DNA database does not necessarily imply guilt, as one recent case showed. An innocent man was charged with murder because his DNA was found on the fingernails of someone killed during a botched robbery. But it was later proved that he had never met the murdered person, or been to the house where the murder took place. In fact, he was indisputably in a local hospital at the time of the murder.
It turned out that the ambulance crew who had taken him to the hospital that day were later called to where the murder in question took place. Somehow, the ambulance team carried with them the DNA of the accused man, and left it on the body of the victim. Even though the quantity of genetic material involved was minuscule, today’s DNA amplification techniques are such that it is possible to extract long enough genetic sequences from these kind of situations to allow them to be matched with DNA database entries. Ironically, the very sensitivity of DNA forensic techniques means that cases of innocent people being accused of crimes are likely to become more common. The problem is that we shed and leave our DNA on everything we touch, even where we stand, and so it is possible for it to be picked up and transferred somewhere else – even on to a murder victim.
That story revealed one kind of false positive problem, caused by technological advances. Another recent crime investigation involving DNA reveals a different kind of error that can lead to privacy problems. It concerns the so-called Golden State Killer, who raped at least 51 women and killed 12 people. The 72-year-old suspect recently arrested was identified as likely to be the person responsible through a novel use of DNA-based genealogy sites. Information about DNA found at some of the crime scenes was uploaded to the site GEDmatch.com, which uses genetic profiles provided by members of the public to help construct family trees. This produced some partial matches with others on the database, indicating that they were relatives of the murderer. By drawing up a family tree containing some 1000 people, the investigators were able to work out who among those might be a suspect.
There are two important privacy issues here. One is that the use of family trees constructed with the aid of DNA represents a fairly inexact way of identifying suspects. Indeed, the first name obtained using this method, defined by the investigators as a “weak match”, turned out to have nothing to do with the case. However, the 73-year-old was interviewed by the police and asked to provide a DNA sample – a stressful procedure for anyone. The imprecise nature of family trees means that potentially dozens of people could have found themselves in this situation, and ordered to provide DNA, a serious invasion of their privacy.
The second point concerns the far-reaching nature of DNA data. When someone uploads their genetic profile to a public database, they are also exposing information about the DNA of hundreds of their near relations, whether or nor the latter want this highly-personal data revealed. A single upload may be providing data that leads to relatives being arrested and forced to provide DNA samples, even if they are innocent of any crime.
As with the false positives caused by accidential DNA transfers, this problem is likely to become worse as more genetic profiles are uploaded, and computers become more adept at reconstructing large-scale family trees from them. The chief science officer of MyHeritage.com recently created from open genealogy data a 13-million-person family tree. Soon it is likely we will have family trees for most people in Western societies, allowing the police to use DNA found at crime scenes to draw up extensive lists of possible suspects on a routine basis. As a report in the LA Times notes, this is part of a wider development in police methods:
The rise of big data, whether it’s publicly searchable DNA databases or records from cellphone towers, has inverted traditional investigative tactics. Previously, law enforcement relied on evidence to build a case around an individual, then sought a warrant from a judge to confirm those suspicions. Modern tactics, enabled by technology, allow law enforcement to trawl a wider – and more indiscriminate – pool before narrowing in on a specific individual.
Another technology that allows the police to cast a wide net without worrying about the privacy implications of doing so is facial recognition. As Privacy News Online reported last year, the British police are using systems to scan crowds and spot individuals on their wanted list. However, as with family trees built using partial DNA matches, the results are not necessarily reliable. A new report from Big Brother Watch in the UK reveals that the use of facial recognition systems there is generating huge numbers of false positives. The Metropolitan Police’s facial recognition matches are 98% inaccurate, which led to the misidentification of 95 people as criminals at last year’s Notting Hill Carnival in London. Despite this, the police force is planning seven more deployments this year. An article in the Guardian points out the dangers of this constant, covert surveillance:
There is no escaping it – especially when you don’t know it’s happening. And if you are one of the unlucky ones who is falsely identified as a match, you might be forced to prove your identity to the police – or be arrested for a crime you didn’t commit.
It’s not hard to imagine the chilling effect its unrestricted use will have. Constant surveillance leads to people self-censoring lawful behaviour. Stealthily, these measures curb our right to protest, speak freely and dissent. They shape our behaviours in ways that corrode the heart of our democratic freedoms.
A 98% false positive rate means the system is identifying large numbers of innocent people as potentially of interest to the police. The stated intention to deploy it more widely suggests the authorities are not too worried about the harm this will cause to the privacy of those erroneously picked out in this way. Perhaps there is a naive belief that the more advanced the technology, the more useful it will be. Both DNA tests and facial recognition show that’s not the case. The threat to privacy is likely to grow as these and other systems are rolled out around the world – the “genetic genealogy” approach is already being applied to 100 other unsolved cases. The key issue is a lack of understanding of the false positives problem inherent in applying fuzzy matching to trawl through large holdings of highly-personal data.
Featured image by National Human Genome Research Institute.
