En quoi consiste l’extraction de données (data scraping) ? (Définition, utilisations et légalité)

L’extraction de données consiste, en termes simples, à utiliser un logiciel afin de collecter des informations à partir de sources numériques (sites Internet, PDF, applications mobiles ou systèmes d’entreprise obsolètes) et à les structurer sous forme de tableur, de base de données ou de fichier au format XLSX.
Il s’agit en quelque sorte d’une version automatisée du copier-coller. Plutôt que de passer des heures à collecter des données manuellement, un programme effectue cette tâche complexe en quelques secondes. Cette technique est désignée par différents noms : « data scraping », « extraction de données » ou « collecte automatisée de données », mais ces termes renvoient à la même pratique ; la récupération de données à grande échelle afin de faciliter leur exploitation.
En substance, l’extraction de données vise l’efficacité et le volume : rassembler des informations déjà disponibles et les rendre exploitables à des fins d’analyse et de prise de décision.
Principes fondamentaux de l’extraction de données
Le data scraping (ou extraction de données) est un terme générique désignant tout processus d’extraction automatisée de données dans divers formats et environnements. Si les sites Internet constituent la source la plus visible, l’extraction de données s’étend bien au-delà du Web ouvert. Dans la pratique, les données sont généralement extraites à partir de :
- Sites Internet et tableaux accessibles en ligne
- Pages publiques et vérifiées, y compris les pages LinkedIn utilisées pour la recherche
- Rapports, factures et fichiers PDF exportés
- Documents numérisés traités par reconnaissance optique de caractères (OCR)
- Outils d’entreprise plus anciens et tableaux de bord ERP sans exportation ni API
Il s’agit en quelque sorte d’un nettoyage numérique d’informations désordonnées. Au lieu de copier manuellement des lignes, des captures d’écran ou des chiffres, le logiciel analyse tout en quelques secondes et organise soigneusement les données dans des colonnes, des graphiques ou des tableaux de bord.
Vous n’avez donc pas besoin de compétences techniques particulières pour y parvenir. Excel Power Query peut extraire et actualiser des tableaux Web directement dans des feuilles de calcul. Des extensions de navigateur, comme Data Miner, et des plateformes no-code, comme WebHarvy, simplifient la mise en œuvre de petits projets, tandis que des outils professionnels, comme Import.io, s’appuient sur l’IA pour gérer des flux de travail évolutifs à plus grande échelle.
Fonctionnement de l’extraction de données

Si les méthodes varient, la plupart des opérations d’extraction de données suivent le même processus général :
- Identification de la cible : déterminez la source des informations que vous souhaitez extraire : site Internet, catalogue au format PDF ou portail Internet d’entreprise interne abritant des données structurées.
- Récupération du contenu : l’outil envoie des requêtes « GET » automatisées ou lance un navigateur sans interface graphique afin de charger les pages comme le ferait un utilisateur.
- Analyse de la structure : le programme analyse la structure sous-jacente (HTML, DOM, strates de texte ou éléments visuels) à l’aide de modèles, tels que XPath et regex, afin d’identifier les données clés (titres, prix, avis, etc.).
- Archivage des résultats : les données extraites sont enregistrées dans un tableur, un fichier au format JSON ou une base de données, ce qui facilite leur filtrage, leur analyse ou leur importation dans d’autres systèmes.
De nos jours, l’IA se charge d’une grande partie de ce travail fastidieux : identification des mises en page, estimation des champs importants et utilisation de modèles de vision pour lire le texte contenu dans les images.
Méthodes courantes d’extraction de données
Voici quelques exemples courants :
- Extraction de données Web : collecte de données à partir de sites en ligne (avis, descriptions de produits ou pages de tarification) afin de garder un œil sur la concurrence ou d’observer l’évolution des tendances du marché.
- Capture de données d’écran : automatisation des clics et des chemins de menu qu’un utilisateur suivrait naturellement au sein d’une interface existante. Cette méthode peut sembler laborieuse, mais elle constitue souvent le seul moyen d’extraire des données provenant de systèmes obsolètes dépourvus d’options d’exportation.
- Extraction de rapports : récupération d’informations structurées à partir de rapports exportés, de tableaux HTML ou de fichiers PDF afin que les outils d’analyse puissent les exploiter ultérieurement.
Dans de nombreuses entreprises, l’extraction s’effectue discrètement, en arrière-plan. Les équipes financières peuvent extraire les champs des factures (nom du fournisseur, montant, date d’échéance) et les intégrer directement dans le logiciel de comptabilité. Les recruteurs et les équipes commerciales peuvent également gagner du temps en collectant automatiquement des listes de clients potentiels à partir d’annuaires professionnels ou de pages LinkedIn, plutôt que de parcourir les profils un par un.
En combinant cette pratique avec l’IA et l’automatisation robotisée des processus, les données extraites peuvent même être transférées en temps réel, transformant ainsi des fichiers poussiéreux en tableaux de bord dynamiques qui aident réellement les utilisateurs à prendre des décisions plus rapides et plus claires.
À quelles fins des particuliers et des entreprises extraient-ils des données ?
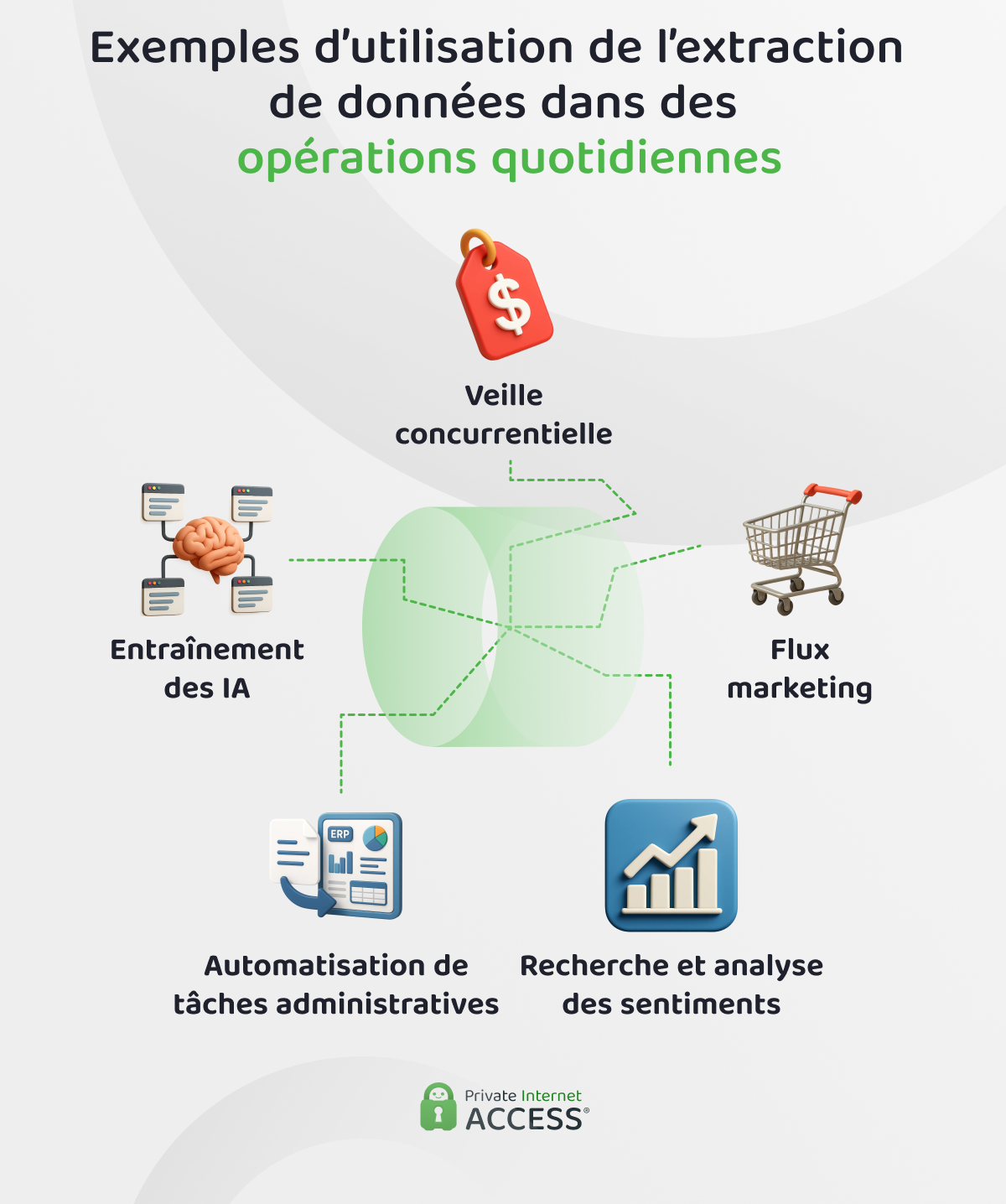
L’extraction de données est largement utilisée dans de nombreux secteurs, car elle réduit le travail manuel et accélère la prise de décision. Voici quelques cas d’utilisation courants :
- Veille concurrentielle : des détaillants et des entreprises commercialisant des SaaS surveillent les prix, les lancements de nouveaux produits et les niveaux de stock de leurs concurrents en temps quasi réel afin d’ajuster leur stratégie à la volée.
- Flux marketing : des équipes de commerce en ligne utilisent l’automatisation afin de synchroniser parfaitement les catalogues Google Shopping et les annonces publicitaires ; des heures de mises à jour manuelles sont ainsi remplacées par quelques clics.
- Recherche et analyse des sentiments : des analystes collectent les avis, les publications sur les réseaux sociaux et les discussions dans les communautés afin de mesurer ce que les clients pensent réellement d’une marque ou d’un produit.
- Automatisation des opérations administratives : des services financiers numérisent les factures et les reçus grâce à une collecte structurée, les champs présents dans ces documents sont directement transférés à des outils comptables afin d’accélérer le processus d’audit.
- Données d’entraînement des IA : les grands modèles linguistiques (LLM) et visuels s’appuient toujours sur d’énormes ensembles de données publiques, dont une grande partie provient de l’extraction automatisée.
Les risques et les utilisations abusives de l’extraction de données
L’extraction de données ne constitue pas en soi un danger. Il s’agit d’une opération neutre, comparable à un couteau de cuisine ou un navigateur Web. Ce qui importe, c’est de savoir qui l’utilise et à quelle fin.
Cela étant dit, les utilisations abusives ont incité les régulateurs et les plateformes à redoubler de vigilance, en particulier dans les cas suivants :
- Vol de contenu : des sites Internet entiers (articles, avis, pages produits) sont copiés ligne par ligne et republiés sans mention de la source. Parfois, ce contenu est même utilisé pour entraîner des modèles d’IA sans autorisation.
- Collecte d’adresses électroniques et hameçonnage : des personnes malintentionnées récupèrent les pages de contact et les coordonnées sur LinkedIn afin de mettre en place des campagnes de spam ou d’hameçonnage particulièrement réalistes.
- Bots de suivi des prix : certains détaillants récupèrent les prix de leurs concurrents en temps réel afin de proposer automatiquement des tarifs plus avantageux.
- Atteintes à la vie privée : ce n’est pas parce que des informations sont « publiques » que leur collecte à grande échelle ne constitue pas une atteinte à la vie privée. Clearview AI est un exemple bien connu : l’entreprise a collecté des milliards de photos sur les réseaux sociaux afin de constituer une base de données dédiée à la reconnaissance faciale, ce qui constitue une atteinte majeure au respect de la vie privée en ligne et continue de faire les gros titres.
- Saturation des serveurs : un nombre excessif de requêtes automatisées simultanées peut saturer un site et le mettre subitement hors service.
L’extraction de données est-elle légale ?
La légalité de l’extraction de données dépend en réalité de la méthode employée et du lieu où elle est effectuée. Les lois ne considèrent pas toutes les formes de cette pratique de la même manière ; ce qui est considéré comme de la « recherche » dans un pays peut être considéré comme un accès non autorisé dans un autre.
En règle générale, l’extraction de données issues de contenus accessibles au public est plus susceptible d’être autorisée lorsqu’elle n’implique pas de contournement des restrictions techniques, de violation des conditions d’utilisation d’un site ou d’utilisation abusive des données. Cependant, le motif seul (tel que l’utilisation à des fins académique ou de recherche) ne rend pas automatiquement l’extraction de données légale, en particulier lorsque des données personnelles sont concernées.
États-Unis (CFAA et hiQ c. LinkedIn)
Pendant des années, le Computer Fraud and Abuse Act (CFAA) a classé la quasi-totalité des accès « non autorisés » aux données dans la même catégorie que le piratage informatique. Cette situation a évolué après quelques décisions judiciaires marquantes. Dans l’affaire hiQ c. LinkedIn, les juges ont précisé que l’extraction de données à partir de pages accessibles à tous (sans connexion ni paiement) ne constituait pas un « accès non autorisé » au sens du CFAA.
Cette décision ne rend toutefois pas cette pratique sans risque. Les entreprises peuvent toujours intenter une action en justice sur la base du droit des contrats (notamment pour violation des conditions d’utilisation), de la protection des droits d’auteur ou du vol de secrets commerciaux, en particulier si les données récupérées sont utilisées à des fins lucratives, partagées à nouveau ou exploitées au-delà de ce qui est autorisé.
Union européenne et Royaume-Uni (RGPD et protection juridique des bases de données)
En Europe, les règles sont plus strictes. Le RGPD s’applique même si les données étaient publiques, car « public » n’est pas synonyme de « consentement ». Si les données collectées contiennent des identifiants personnels, vous devez disposer de motifs légaux valables pour les traiter, tels qu’un intérêt légitime ou un consentement.
Mais disposer d’une base juridique ne suffit pas toujours. Le RGPD impose également le respect d’obligations supplémentaires, notamment la minimisation des données traitées, la limitation des finalités, des restrictions relatives à la conservation, des contrôles de sécurité appropriés et, lorsque les risques sont plus élevés, une analyse d’impact relative à la protection des données (AIPD). Chacun de ces facteurs est évalué dans son contexte, en particulier lorsque la collecte de données est effectuée à grande échelle.
Un autre aspect doit également être pris en compte : la protection juridique des bases de données. La copie d’un ensemble de données structuré (par exemple, un catalogue complet de produits ou des archives tarifaires) peut enfreindre les lois sur la protection des bases de données, même si chaque donnée prise individuellement n’est pas protégée par le droit d’auteur. Le fait de limiter la collecte au strict nécessaire pour la réalisation de l’analyse définie et d’éviter la copie intégrale des données peut contribuer à réduire l’exposition, mais cela ne supprime pas les obligations légales.
La zone grise de l’IA
La situation est plus complexe concernant les données utilisées pour entraîner les IA. Des plateformes comme Reddit, Stack Overflow et de grands éditeurs poursuivent en justice des entreprises spécialisées dans l’IA pour avoir exploité leur contenu sans leur consentement afin d’entraîner leurs modèles.
Certains invoquent d’anciennes lois, comme celle sur la violation de propriété privée, en arguant que les sites Web sont des propriétés privées et que leur exploitation à grande échelle « épuise » leur infrastructure sans autorisation. Il s’agit encore d’un flou juridique, mais l’issue de ces conflits juridiques déterminera le degré d’ouverture réel du Web.
Vérification rapide de la conformité
✅ Limitez-vous aux données publiques pour un usage personnel ou analytique.
✅ Supprimez ou anonymisez les informations personnelles avant de les conserver.
❌ Ne contournez pas les identifiants, les CAPTCHA ou les systèmes de paiement ; c’est là que s’arrête le domaine « public ».
❌ Si un site vous bloque ou vous avertit, arrêtez-vous. Cela constitue une limite à ne pas franchir.
Comment les sites Internet se protègent-ils contre l’extraction de données ?

L’extraction de données Web est si courante que presque tous les grands sites Internet ont mis en place des mesures de protection s’exécutant en arrière-plan. L’objectif n’est pas de rendre l’extraction impossible (la bataille serait perdue d’avance), mais de ralentir le processus et de le rendre suffisamment coûteux pour dissuader les acteurs malveillants.
Voici comment ces protections fonctionnent en pratique :
- Limitation du nombre de requêtes : chaque adresse IP ou session de navigation n’est autorisée qu’à un certain nombre de requêtes par seconde. Si cette limite est dépassée, le site vous bloque ou vous met en attente, ce qui est une manière polie de vous signaler qu’il vous a détecté.
- CAPTCHA et défis liés au navigateur : ces actions nécessitent de petites actions humaines (cliquer sur des cases, résoudre des énigmes) que des robots basiques sont incapables d’effectuer.
- Randomisation HTML : les sites modifient discrètement la structure de leurs pages, ce qui empêche tout outil d’extraction de données s’appuyant sur un format fixe ou un encodage obsolète de fonctionner.
- Obfuscation des données : les données à caractère personnel (comme les adresses électroniques, les logiques tarifaires ou les noms des fournisseurs) sont dissimulées dans des images, des scripts ou des API protégées, ce qui rend l’extraction en masse plus difficile.
- Gestion des robots au niveau de la périphérie du réseau : les CDN, comme Cloudflare, filtrent le trafic suspect avant qu’il n’atteigne le site principal, détectant les comportements automatisés à une grande distance.
L’avenir de l’extraction de données et de l’accès éthique
Tandis que les données continuent de s’imposer comme la matière première la plus précieuse au monde, le futur de la collecte de données évolue progressivement de l’extraction vers l’autorisation. L’époque où l’on pouvait extraire toutes les données disponibles est révolue. Aujourd’hui, la question est de savoir qui est autorisé à accéder à quelles données et dans quelles conditions.
Plusieurs tendances contribuent à cette évolution :
- Accords de licence et de données payantes : de plus en plus d’entreprises vendent désormais un accès structuré à leurs ensembles de données via des API par abonnement ou des partenariats négociés. Ce qui relevait auparavant d’une zone grise juridique devient un élément à part entière des contrats.
- API et programmes de chercheurs de confiance : des plateformes, comme Reddit, X et Google, remplacent l’extraction libre de données par des canaux vérifiés où des universitaires ou des développeurs agréés peuvent collecter des données en toute transparence.
- Blocage des bots IA : les fournisseurs de solutions de sécurité forment désormais des outils de pointe pour détecter et bloquer par défaut les robots d’indexation IA non autorisés (ce qui représente une menace croissante, car les LLM aspirent le contenu Web sans consentement).
Plus généralement, la transparence et la confidentialité ne sont pas incompatibles ; elles évoluent ensemble. La prochaine phase de l’automatisation ne consiste pas à bloquer tout accès aux données, mais à mettre en place des systèmes garantissant un accès éthique, vérifiable et équitable à toutes les parties concernées.
FAQ
En quoi consiste l’extraction de données (data scraping) ?
L’extraction de données désigne le processus automatisé consistant à collecter des informations à partir de sources numériques (comme des sites Web, des fichiers PDF ou des applications) et à les convertir dans un format structuré, tel qu’un tableur ou une base de données. Cela permet aux utilisateurs d’analyser les données plus rapidement sans avoir à effectuer de copier-coller manuel, bien qu’il soit toujours nécessaire de respecter les conditions d’utilisation du site et les lois sur la confidentialité.
En quoi consiste l’extraction de données Web et quel est son fonctionnement ?
L’extraction de données Web se concentre spécifiquement sur le contenu disponible en ligne. Des logiciels ou des robots aspirent le contenu d’une ou plusieurs pages Web, identifient la structure de leur code HTML, extraient les informations nécessaires (comme les prix ou les avis) et les enregistrent dans un fichier ou un tableau de bord exploitable. Les outils modernes recourent souvent à l’IA et à la reconnaissance optique de caractères pour détecter automatiquement les éléments.
L’extraction de données est-elle légale ?
Cela dépend de la source des données, de la législation locale en vigueur et de l’utilisation prévue. L’extraction de données publiques peut être autorisée dans certains contextes, tandis que la collecte automatisée de données privées ou protégées est contraire à la loi ou aux conditions d’utilisation. Respectez toujours les consignes contenues dans le fichier robots.txt et les politiques du site avant de vous adonner à cette pratique.
Quels sont les cas d’utilisation courants de l’extraction de données ?
Les entreprises et les particuliers ont principalement recours à l’extraction de données afin de gagner du temps, de réduire les tâches manuelles et de faciliter la prise de décision basée sur les données. Parmi les cas d’utilisation courants, citons l’extraction de données structurées, la recherche sur la concurrence et l’analyse des sentiments.
Comment les sites Internet peuvent-ils se protéger contre l’extraction de données non autorisée ?
Les sites Web adoptent souvent plusieurs approches, notamment des limitations de débit, des CAPTCHAS et la détection des robots, afin de bloquer les requêtes automatisées. Ces mesures ralentissent l’extraction et la rendent moins rentable, sans toutefois la rendre impossible.
L’utilisation d’un VPN affecte-t-elle ou masque-t-elle l’activité d’extraction de données ?
Un VPN dissimule uniquement la véritable adresse IP d’un utilisateur et chiffre le trafic ; il ne rend pas l’extraction de données indétectable ou légale. Les sites Internet peuvent toujours reconnaître les activités automatisées grâce au rythme, aux en-têtes et à la nature des requêtes. Les VPN sont davantage destinés à la protection de la vie privée sur les réseaux Wi-Fi publics qu’au contournement des restrictions en matière d’extraction de données.
